The ETRPA is designed to optimize a multi-objective function by:
1. Maximizing packing density.
2. Minimizing overlap between shapes in a configuration.
This is achieved through the use of a penalty function, which generally works quite effectively. However, there are some downsides to this approach. Many generated samples are flagged as unfeasible, leading to inefficiency. Additionally, some potentially good configurations with minimal overlaps are discarded. A more effective approach would involve mapping unfeasible solutions to feasible ones, essentially repairing the overlaps.
I’ve designed a relatively straightforward method to accomplish this almost analytically. It boils down to finding roots of a second-order polynomial, which is essentially a high school algebra problem. Admittedly, you’ll need to solve quite a few of these second-order polynomials, but they are relatively easy to handle.
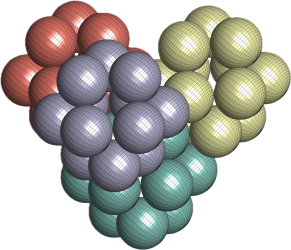
So, with this approach, you can now map a configuration with overlap/s
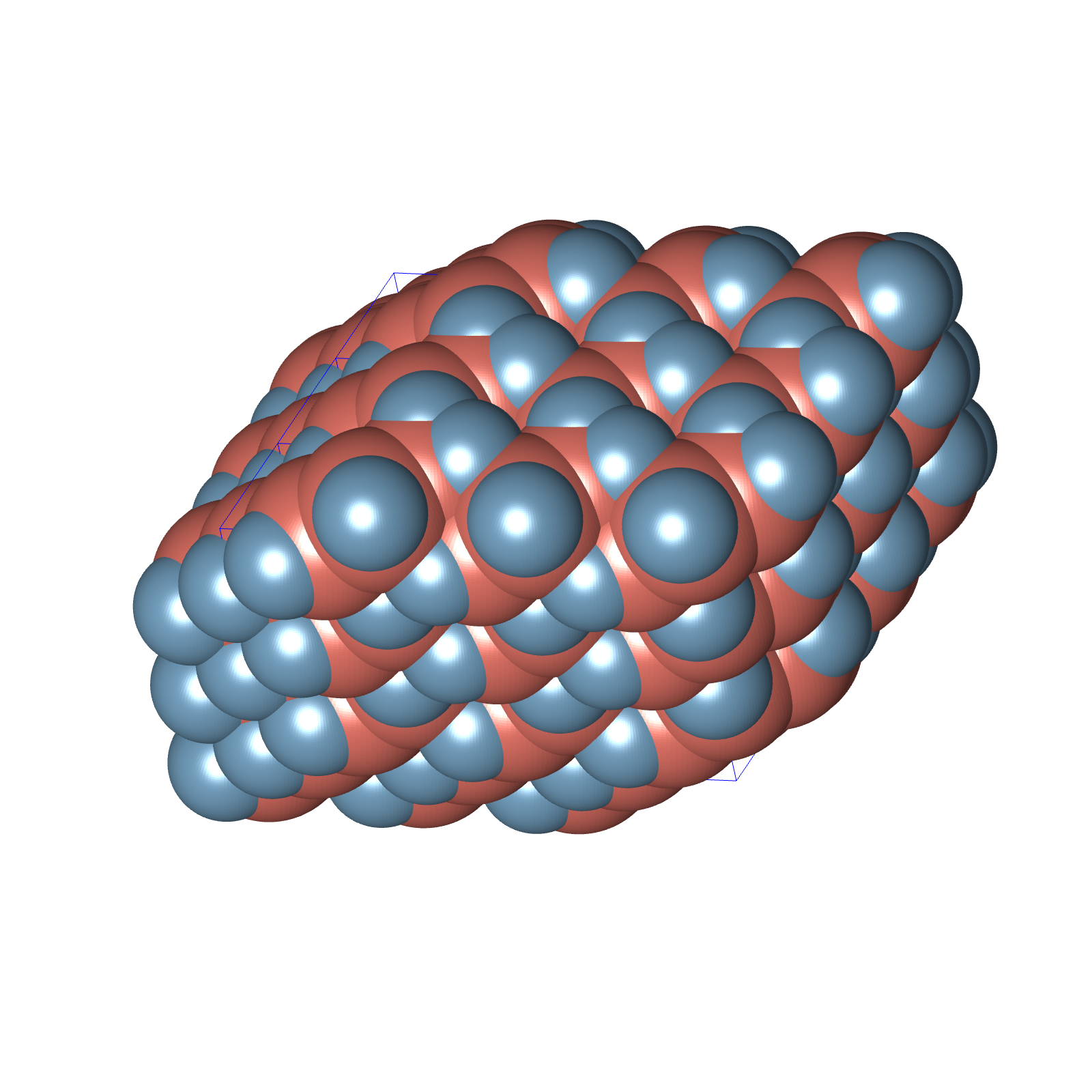
to one without overlaps

Now, a couple of new issues have cropped up. First, there are some seriously bad solutions that are being sampled. For example, consider this one:

which is then mapped to this configuration

This is not helpful at all. Second, the parameters of this configuration are way above the optimisation boundaries that were used to create all configurations. As a result, it falls outside the configuration space where my search is taking place.
To address this issue, after repairing the configuration, I conduct a check to determine if the repaired configuration falls within my optimization boundaries. Any configurations that fall outside of these bounds are labeled as unfeasible solutions.
It might seems this puts me back in the same situation of multi-objective optimization, but that’s not the case. In my scenario, the Euclidean gradient at time  takes this form:
takes this form:
 .
.
Here,  represents the mean of all samples in the current batch, and I only consider the configurations without overlap or the repaired ones that lie within the optimization boundaries for
represents the mean of all samples in the current batch, and I only consider the configurations without overlap or the repaired ones that lie within the optimization boundaries for  . This effectively means I’ve eliminated the need for the penalty function and am optimizing only based on the objective function given by the packing density.
. This effectively means I’ve eliminated the need for the penalty function and am optimizing only based on the objective function given by the packing density.
This is a promising, but it does introduce another problem. When I repair some of the unfeasible configurations, I end up making slight alterations to the underlying probability distribution, shifting it slightly from 

to 

The issue here is that if I were to compute the Natural gradient as I used to, I’d obtain  in the tangent space
in the tangent space  of the statistical manifold, where everything is unfolding, but what I actually need is
of the statistical manifold, where everything is unfolding, but what I actually need is  in the tangent space at the point .
in the tangent space at the point .
Fortunately, the statistical manifold of the exponential family is a flat Riemannian manifold. So, first, I move from to  using this vector
using this vector  (where corresponds to the dual Legendre parametrization of , and
(where corresponds to the dual Legendre parametrization of , and  to
to  ), and then I compute the natural gradient at the point .
), and then I compute the natural gradient at the point .
In addition, to increase the competition within my packing population, I introduce a sort of tournament by retaining the N-best configurations I’ve found so far and incorporating them with the repaired configurations from the current generation. This leads to yet another slightly modified distribution, 
and I have to perform the same Riemannian gymnastics once more. In the end, the approximation to the natural gradient at the point is as follows





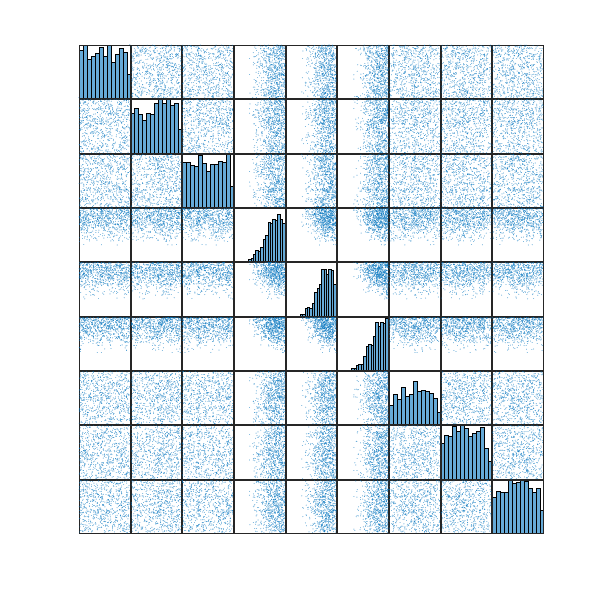
So far, experiments show that these modifications to the ETRPA are far more effective than the original ETRPA. Here’s a visualization from one of the test optimization runs:
In this particular run, the best packing I achieved attains the density of  . Previously, reaching such a level of density required multiple rounds of the refinement process, each consisting of
. Previously, reaching such a level of density required multiple rounds of the refinement process, each consisting of  iterations. Now, a single run with just
iterations. Now, a single run with just  iterations is sufficient. It’s worth noting that even after only
iterations is sufficient. It’s worth noting that even after only  iterations, the algorithm already reaches areas with densities exceeding
iterations, the algorithm already reaches areas with densities exceeding  .
.
It’s important to mention that currently, I’ve only implemented the repair process for unfeasible configurations for the  space group. However, similar repairs can be done for configurations in any space group. Furthermore, the algorithm’s convergence speed can be further enhanced by fine-tuning its hyperparameters. Perhaps it’s time to make use of the BARKLA cluster for the hyperparameter tuning.
space group. However, similar repairs can be done for configurations in any space group. Furthermore, the algorithm’s convergence speed can be further enhanced by fine-tuning its hyperparameters. Perhaps it’s time to make use of the BARKLA cluster for the hyperparameter tuning.